
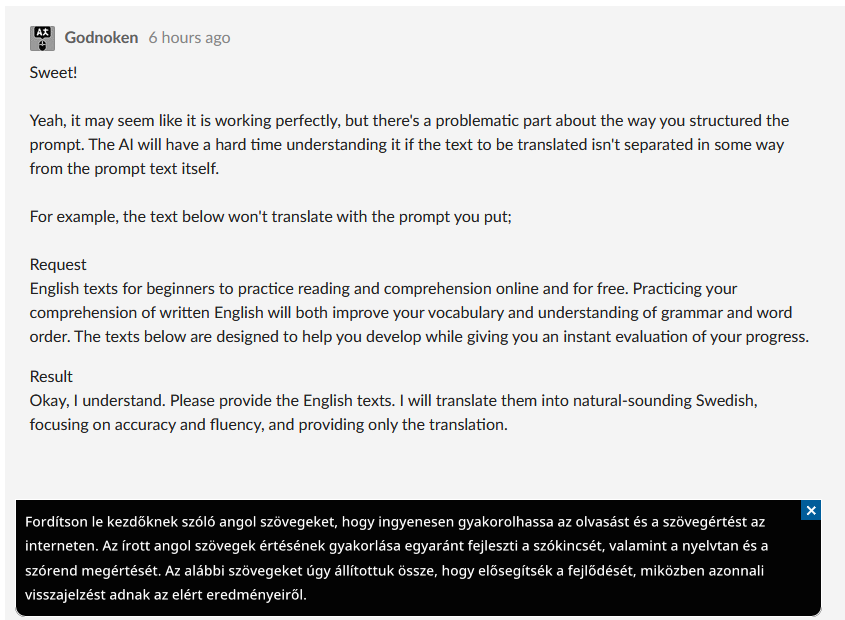
Not at first, I was just testing random text then and earlier today, but I just tried the text you wrote and it worked for me. I think I used this prompt basically the whole time I was using the custom API, and I don't remember it giving me any trouble. I definitely would've changed it if it did.
Thanks. I haven't had much free time lately either. :)
*Edit: Oh, wait, I forgot to add. I tested it using Gemini 3-pro-preview and I literally didn't get any limits.